
Совсем скоро нас ждет конференция 8Р и новые доклады. А пока давайте вспомним, что полезного узнали в прошлом году. Делимся конспектами докладов, которые еще не публиковались в сети целиком. Узнайте, как начать работать с bigQuery и ClickHouse, настаивать Data-driven marketing и автоматизировать контекстную рекламу.
Также рекомендуем первую часть докладов с потока для PPC-специалистов.
Как начать работать с bigQuery и перестать думать о сэмплировании
Андрей Осипов, CEO Школа веб-аналитики
Поговорим о том, как сделать, чтобы информация о пользователях, пришедших на сайт, и их действиях отправлялась не только в Google Analytics, но и в bigQuery. И вообще зачем это нужно. Сначала разберем общие проблемы.

Самая большая проблема с Google Analytics — то, что в нем есть лимиты. Это инструмент по умолчанию бесплатный, а версия 360 стоит довольно много. При этом есть большое количество сайтов, где объем трафика или событий большой.
По умолчанию в справке написано, что 500 000 сеансов, и у вас включается семплирование. Т. е. те данные, которые отображаются в ваших отчетах Google Analytics, они будут неточными. Если вы сделаете какой-то отчет, то данные по коэффициенту конверсии, транзакции, revenue будут не реальными, а высчитываемыми.
Google возьмет кусочки первого пользователя, второго, пятнадцатого и на базе этой информации примерно высчитает, какой коэффициент конверсии будет. Эти данные могут быть очень неточными. Когда я пару лет назад проводил обучение, была аудитория человек 50, и каждый выполнял какую-то мою задачку на базе тестового аккаунта Google Analytics. Почти у каждого был свой показатель конверсии и разница была довольно существенная. В одних и тех же датах, в одном и том же отчете, с одними и теми же метриками.
Если данных много, то у каждого пользователя, который работает с аккаунтом Google Analytics, будут свои данные. Если данные у вас неточные, то точные решения вы принять не можете. Разница в 0,1% — это плохо, но несмертельно. А представьте, что коэффициент конверсии в одном случае у вас 1%, а во втором случае 6%. То тут никакие точные данные получить нельзя.
Самые чувствительные данные обычно касаются прибыли, роста, KPI, которые влияют на управление маркетингом. У вас нет доступа к сырым данным для Google Analytics, у вас есть Core Reporting API, сейчас уже версии 4.0. Это позволяет вытащить определенные данные из Google Analytics. Но это все же не доступ к сырым данным. В API тоже включается сэмплирование. Это не решение, если вы хотите интегрировать эти данные с вашими системами, потому что опять-таки нет доступа к сырым данным. К реальным записям каждого посещения.
Если вы когда-то открывали отчет User Explorer, то могли видеть, как пользователи реально «ходят» по вашему сайту. Сколько они делают сессии, и в каждой сессии: вот он зашел, открыл страницу, нажал на кнопку и т. д. Если бы такие данные были в виде таблицы, то с ними можно было бы классно работать.
Как бороться с сэмплированием
Google Analytics 360 (Premium)
Там порог сэмплирования увеличен до 100 млн сеансов, что может покрыть большинство запросов бизнеса. Стоит это много. У нас в Украине есть OWOX, можете с ними пообщаться — они расскажут, сколько. Для многих это будет прекрасным решением, особенно для крупного бизнеса.
Разделение по различным Property
Мы можем хитро делить на различные property (ресурс — прим. Ringostat). В одном property в Google Analytics передавать данные одного подраздела, другое property другого подраздела. Или делить по городам. Но потом возникает проблема, чтобы все это свести в одно место. Т. е. можно это делать какими-то хаками внутри Google Analytics, но обычно это не очень удобно.
Работа с небольшими промежутками времени
Сэмплирование не включится, если у вас немного трафика. Можно выгружать данные, например, на один день, а потом их где-нибудь плюсовать. Допустим выгрузили данные за понедельник, вторник, среду, где-нибудь объединили — и на выходе у вас будет более-менее точный отчет. Но это тоже очень неудобно.
GoogleAnalyticsR (Google Analytics API to R)
Марк Эдмондсон написал для R такой язык программирования. Специальный модуль, который позволяет выгрузить несэмплированные данные. Но он работает не всегда точно и не всегда это несэмплированные данные. Ну и нужно знать R.
Выгрузка сырых данных в bigQuery и ClickHouse
Тут даже не выгружать, а именно стримить. Как только пользователь зашел на сайт и сделал что-нибудь, событие об этом факте уходит в Google Analytics. А мы можем сделать так, чтобы эти данные уходили бы еще куда-нибудь. Лично мне для этой цели больше нравится bigQuery.
Почему bigQuery

Рассмотрим это подробней. Начну с самого большого плюса. В отличие от ClickHouse и других подобных инструментов, Google сам администрирует bigQuery. Вам не нужен специалист, который будет все настраивать, увеличивать квоты и т. д. Вам не нужен сервер. Просто заводите аккаунт, привязываете платежную информацию, стримите — и об остальном больше не думаете. Только платите и не очень много, по сравнению с другими системами.
Вы можете объединять данные с внутренней базой данных. Например, для решения задач скоринга, обогащения данных, машинного обучения. Можете использовать данные по рекламным системам: факту клика и его стоимости из Facebook, Google Ads. Что кстати очень просто — есть AdWords scripts и готовый кусок скрипта в справке по Google AdWords. Вы его копируете, вставляете в AdWords scripts, и данные уходят в bigQuery.
Это быстро и дешево, его не нужно обслуживать. У меня было решение, где мы объединяли мобайл и веб. Допустим, пользователь переходит с веба на мобильную версию или скачивает ее. Тогда мы можем учитывать и мобильную версию в BIGQuery, мобильное приложение и сам сайт. Все это можно держать в одном месте, делать сквозную аналитику.
bigQuery — это часть Google Cloud Platform, где есть множество дополнительных инструментов. В том числе и по машинному не обучению, которые вы все можете использовать.
Как это работает
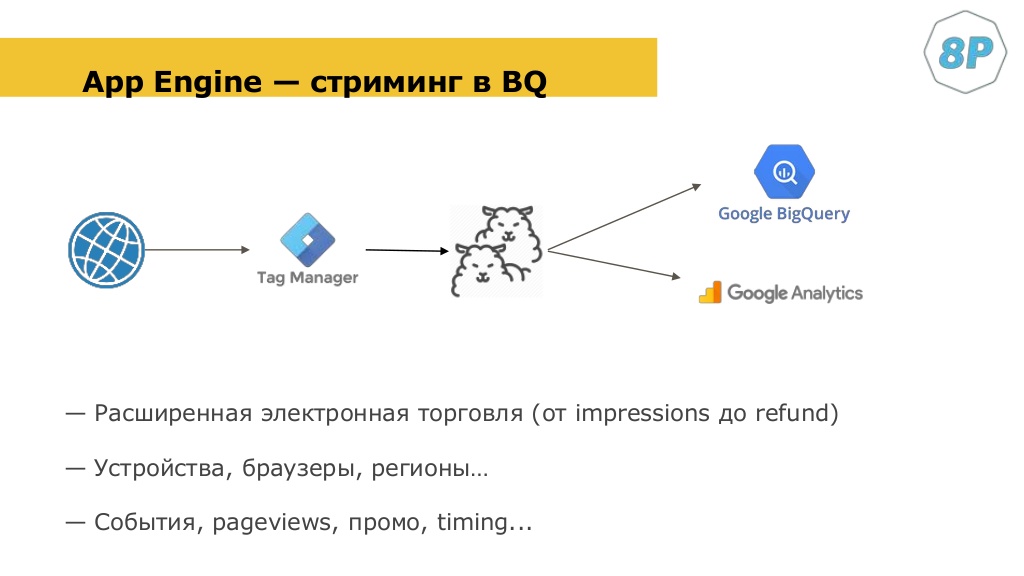
- Пользователь заходит на сайт — отрабатывает Google Tag Manager.
- Внутри него есть специальная переменная. Она клонирует запрос. который должен уходить в Google Analytics.
- После чего отправляет его в bigQuery.
Те теги, которые вы настроили в Google Tag Manager, с теми настройками, которые вы хотите отправить в Google Analytics, вы можете по умолчанию отправлять в bigQuery. Причем все: расширенную электронную торговлю, данные об устройстве, браузеры, события и т. д.
Мое решение построено на базе решения Александра Ерошкина, которое он написал года два назад — оно очень простое. Я его допилил, сделал расширенную интернет-торговлю и т. д. Но если вы захотите повторить это в базе, то можете пойти по такому же пути.
У меня в блоге есть статья, как вы можете установить себе это решение и начать стримить с нуля. Чтобы начать это делать, потребуется всего полчаса.
Инструменты
Мы используем:
- bigQuery;
- App Engine — это еще одна часть Google Cloud Platform, он обрабатывает те данные, которые мы отправляем из Google Tag Manager — этот дублированный хит;
- Power BI или Google Data Studio — чтобы работать с этими данными.
Выглядит это следующим образом. У вас есть data set, в котором есть несколько табличек. Каждая из них будет отвечать за что-то свое. Например, эта табличка отвечает за стриминг с веба:
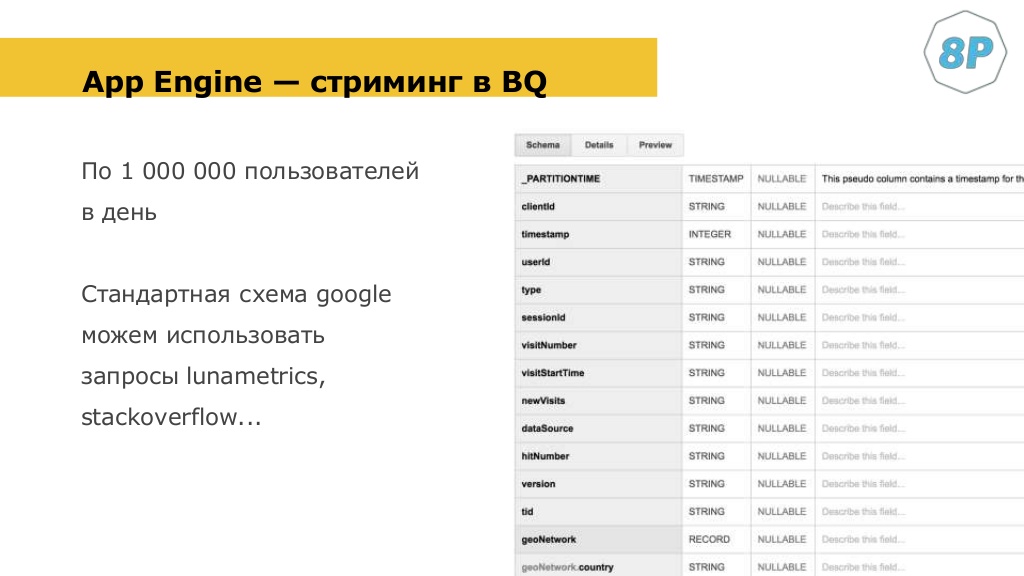
Это точно такая же таблица, как в Google Analytics 360. Это довольно хорошо, потому что на Stack Overflow на Lunametrix, если вы читаете блоги, есть довольно много готовых решений.
Вот более общая схема, которая это иллюстрирует:
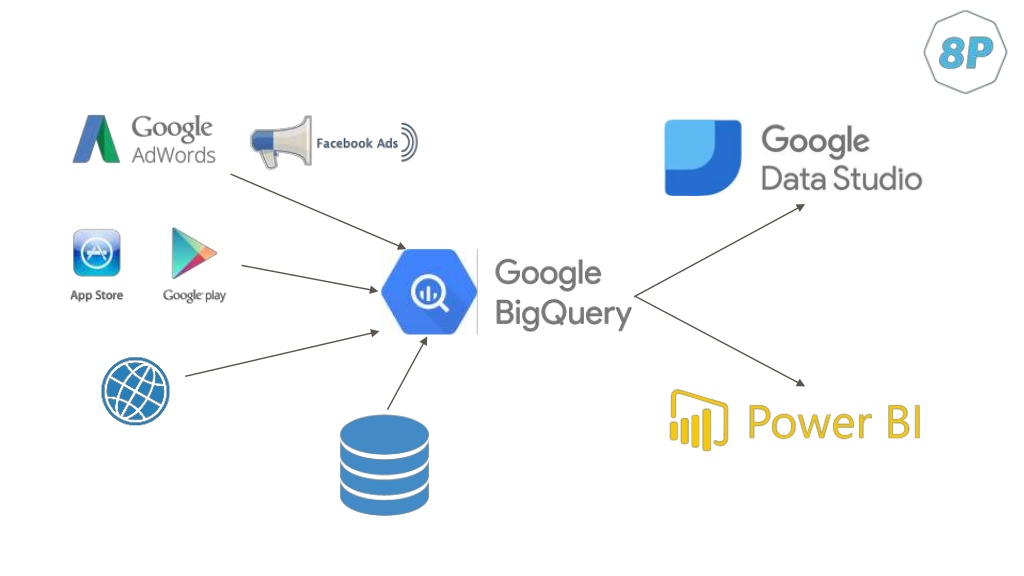
- Есть рекламные аккаунты, мы стримим это в bigQuery. Есть данные с мобильных приложений, мы стримим их туда же и т. д.
- Объединили все это.
- Потом делаем дашборды, такие, как нам надо.
При этом у нас есть возможность, используя тот же App Engine, реализовывать модули, интегрироваться с другими системами.

Разберем пару моментов немного подробней.
- Нет срезов. Если вы работаете в Google Analytics, вы знаете, что не можете некоторые типы данных объединять. Там есть разные скоупы. Есть ограничения по количеству метрик, которые вы можете отображать в отчете. Тут у вас есть доступ к сырым данным, и вы делаете, что хотите.
- Refunds. В Google Analytics рефанды, т. е. возврат денег за транзакцию, если она была отменена, выводится в отдельной колонке и ни на что не влияет. Чтобы это потом посчитать, нужно выгрузить и отнять количество revenue, которое получилось, минус refund. И тогда у вас получатся более-менее точные данные. В bigQuery это можно сделать на лету, и сразу показывать точные данные по реальной прибыли. Без учета транзакций, которые были отменены.
bigQuery — это быстро, и вы получаете fully management. Мне кажется, эти два момента лучше, чем все остальное. Вам не нужно думать об администрировании. И несколько гигабайт информации он может обработать до трех секунд.
Пример отчета Power BI, который мы можем сделать. Это мы на Analyze с желтой кнопкой делали такое решение. Вы можете делать такие отчеты на базе данных из Google Analytics, но источником данных тут будет bigQuery. У вас нет ограничений, как выводить данные, в отличие от Google Analytics.

Google Data Studio запилил новую функцию, которая позволяет объединять разные таблицы между собой. Чего раньше не было, и это нужно было делать до того, как мы выводим данные. Поэтому многие использовали Power BI.
Data Studio — это тоже инструмент от Google. Он имеет нативный коннектор bigQuery, можно прямо написать запрос, вставить и по нему выводить те данные, которые мы вытащили из bigQuery.
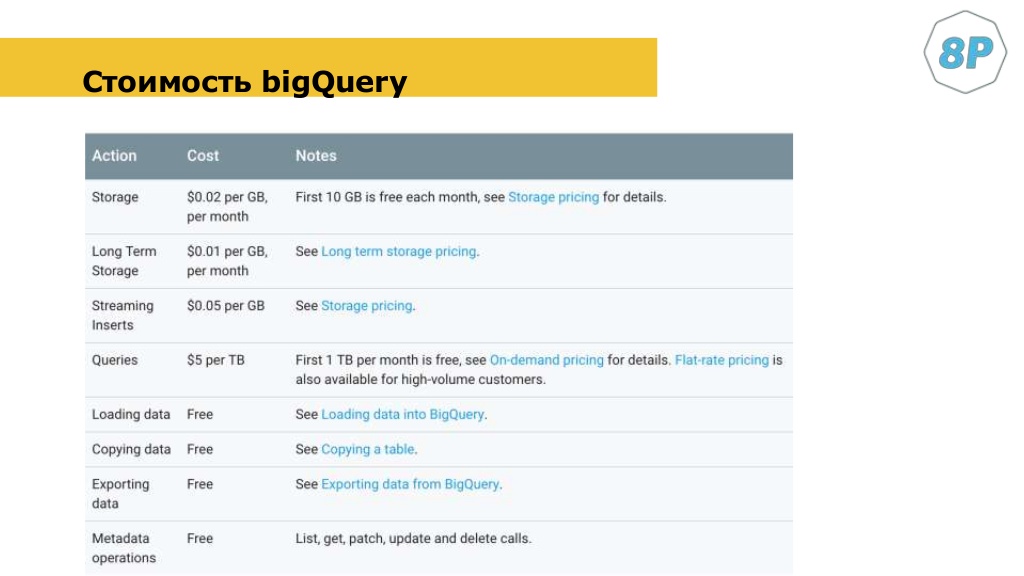
Если у вас 1 млн сессий в день, то в месяц вы будете платить 200-300$. За хранение данных и небольшой процессинг. Если вы будете много работать с bigQuery, то будете платить за данные, которые были обработаны. Допустим, вы оптимизируете запросы и будете не в реальном времени это делать, а каждый день, например. В этом случае вы будете платить немного. Если посещаемость вашего сайта 50— 100 000 в день, то стоимость может быть в размере 50$ в месяц.
Если вы хотите работать с данными, вам нужен SQL. Он простой — это не язык программирования. Ему можно научиться недели за полторы-две. Есть курсы на Кaggle. И есть тестовый набор данных bigQuery, на которых вы можете потренироваться.
Резюме
- это дешево и быстро;
- гибкая система;
- для дополнительных данных используем Google Tag Manager;
- легко масштабируется;
- можно подключить машинное обучение;
- не нужно администрировать.
Принцип «data-driven marketing» в контекстной рекламе
Сергей Довганич, CEO Convert
Кейс №1: B2B-компания
Проект занимается продажей второго гражданства. Особенность — сложный путь клиента и долгий цикл продажи.
Исходные данные:
- стоимость услуг — от 300 000 долларов, это инвестиция в экономику страны, взамен которой дают гражданство;
- цикл продаж достигает 12 месяцев;
- много рекламных касаний с клиентом.
Аудитории мало, трафик дорогой, CPC в контекстной рекламе достигает 12-14$ за клик.
Если клиент принимает решение в течение года, то человек взаимодействует с несколькими рекламными кампаниями. Например, начал поиск через контекстную рекламу Google по запросу «гражданство страны N». Потом его догнал ремаркетинг, имейл, сработала органика, и сделка закрылась. Еще одна сложность — при долгом цикле сделки клиент взаимодействует с брендом с нескольких устройств. Как минимум, в цепочке два-три устройства.

Наша задача — все эти данные свести. Мы решили не придумывать велосипед и взять самую простую модель атрибуции, линейную. Так как продажа осуществляется всего один раз, мы ценность одного клиента делим на количество его сессий.
Допустим, у человека было четыре сессии до покупки. Четверть дохода от чека, который заработала компания, относится к Google cpc, ремаркетингу или другим каналам.
Полезная статья — «Короче: о моделях атрибуции за 3 минуты».
Продажа не заканчивается получением лида, процедура процесса оформления тоже занимает время. В этом промежутке человек тоже взаимодействует с рекламными кампаниями. Поэтому важно учитывать «хвост», который остается после оформления заявки. Рекламные каналы работают на удержание клиента, потому что менеджеры конкурентов тоже работают. И нам нужно всегда подтверждать свою экспертизу.
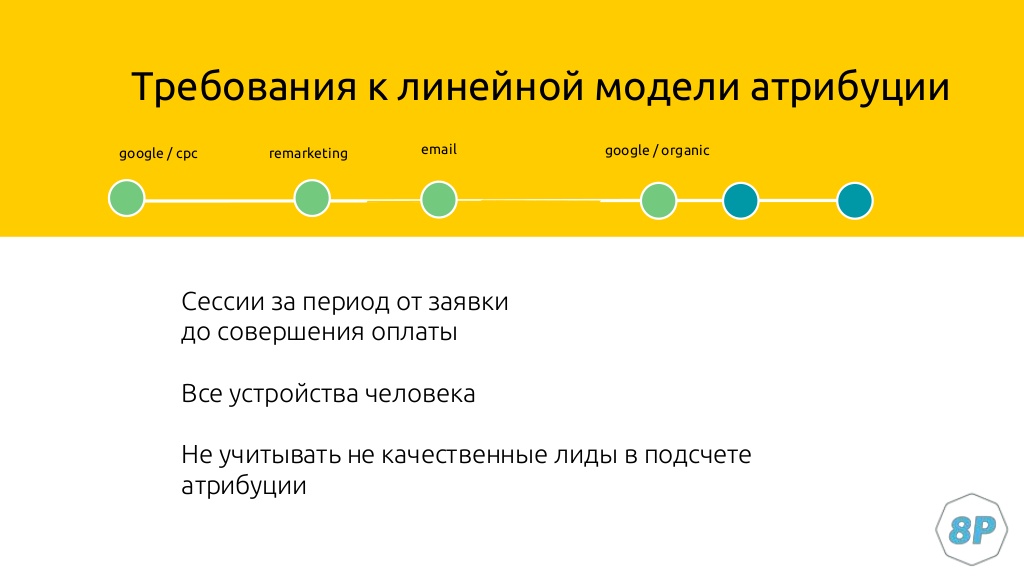
Как построить модель атрибуции
- Cбор сырых данных Google Analytics, SalesForce в ClickHouse.
- Объединение данных Google Analytics с SalesForce и рекламными бюджетами.
- Построение линейной модели атрибуции, визуализация данных в Power BI.
Данные об онлайн-конверсиях хранятся в Google Analytics. SalesForce — это CRM-система, где уже есть информация о продажах. Наша задача свести данные и визуализировать отчеты.
ClickHouse
Это хранилище, колоночная база данных — такая же, как, допустим, bigQuery. Покупаем хостинг, на котором разворачивается впоследствие операционная система Ubuntu. После этого на почту приходят доступы к нему. Сервер — это просто компьютер, на который я должен установить ПО.
Скачиваем расширение, которое позволяет работать с этим сервисом. Вводим логин и пароль, который нам прислали. Процесс детально показан в видео. В результате мы можем заходить по адресу сервера. После этого открывается Tabix — графический клиент для работы с базой данных.
Пару слов о том, чем база данных отличается от Excel. Да, она также хранит информацию в виде колонок. Если в Excel это называется лист, то в базе данных — таблица, которая содержит данные построчно. Вся прелесть в том, что я могу написать запрос к базе SELECT и перечислю, какие данные из базы мне нужны.
Выгрузка данных SalesForce
Как только я собрал данные Google Analytics в ClickHouse, возникает вопрос, как объединить их с данными SalesForce. Данные из CRM можно получить с помощью коннектора. Обычно все сначала хотят делать их сами, и теряют много времени. Но в мире давно существуют платформы, где вы можете выбрать, из какого источника выгрузить данные. Это Renta, Fivetran, Alooma.
Рекомендуем кейс Convert, где описано построение аналитики для клиники. Для этого использовалась в том числе и Renta.
Просто логинимся в платформе. Например, SalesForce. Задаем аккаунт и указываем, какие данные нужно получить. Допустим, данные по лидам, которые будут обновляться каждый час. Выбираем, в какое хранилище данных сохранить. Например, в bigQuery. С этого момента происходит загрузка и обновление данных в базе данных.
Получаем таблицу с набором данных. В данном примере у нас есть client ID, такой же, как есть в Google Analytics, статус заявки по нему в CRM и дата закрытия сделки:
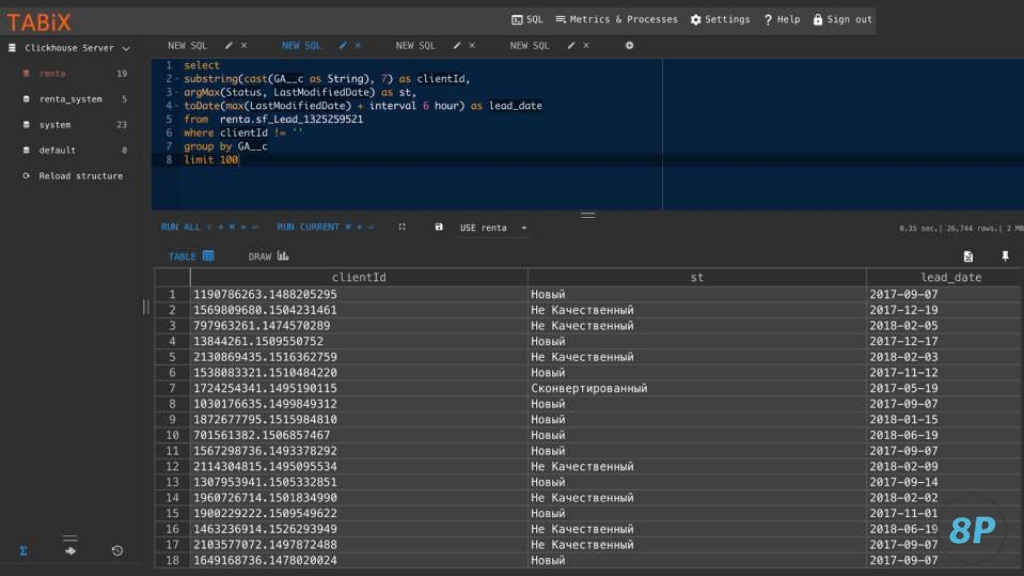
Чем полезны базы данных
Всю обработку данных мы переносим не на сторону Power BI, которая будет очень долго загружаться и отрабатывать — а на сторону ClickHouse. Всю логику расчета метрик нужно переносить на базу данных. Это сильно упрощает работу с отчетами.
Тут у нас client ID Google Analytics сохранялся с дополнительными параметрами. Что мы делаем:

Объединение данных Google Analytics с SalesForce и рекламными бюджетами
Теперь мы можем объединить данные из Google Analytics и SalesForce для построения атрибуции. Делаем это по client ID или по собственным cookie. В данном случае мы использовали второе, потому что это позволяло «опрокидывать» ее на уровне разных устройств.
Весь процесс лидогенерации на сайте происходил так:
- человек заходит на лендинг;
- оставляет свою почту как обязательное условие;
- на почту он получает информацию по определенным программам и если хочет узнать подробнее, то кликает на ссылку;
- в нее всегда вшито собственное cookie;
- если скрипт находит cookie в URL, то обновляет ее.
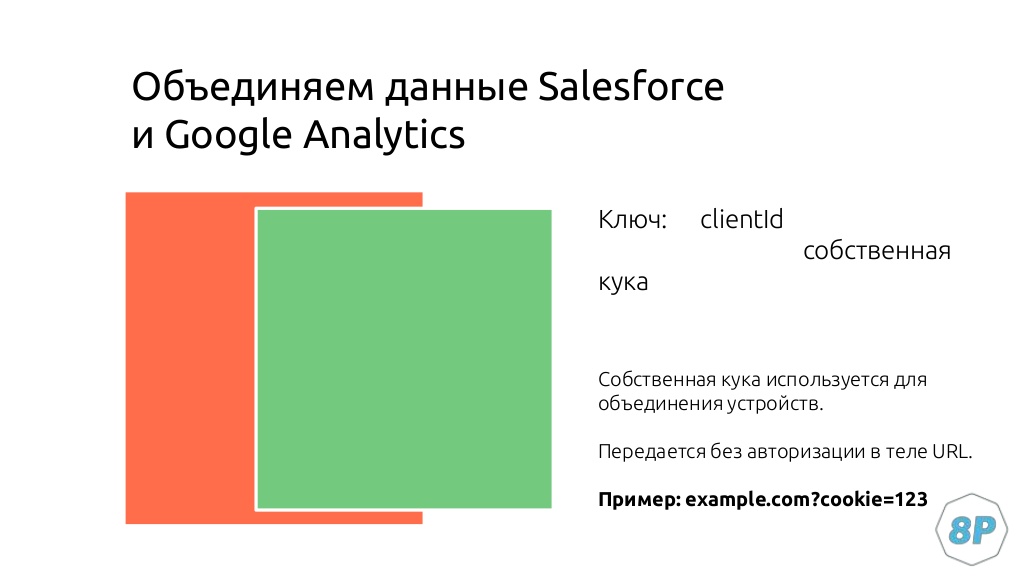
Допустим, клиент оформил заявку через компьютер, перешел по ссылке, а потом по ней же перешел из телефона. В этом случае мы объединяем данные. На выходе получаем:
- client ID из SalesForce и Google Analytics — он везде одинаковый;
- количество сессий в рамках пользователя из Google Analytics;
- статус клиента из SalesForce;
- дата его конвертации в определенный статус.
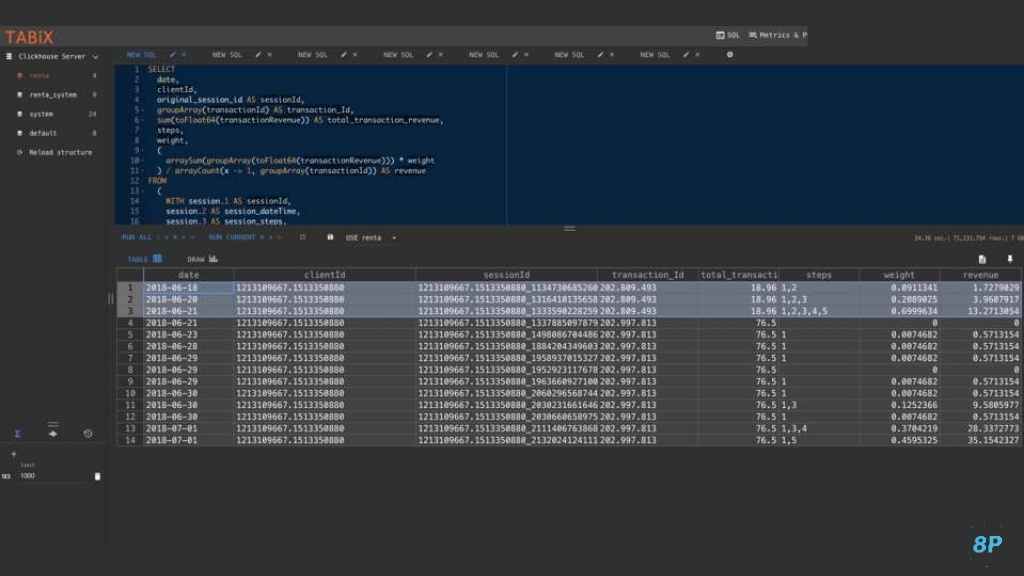
Это пример запроса:
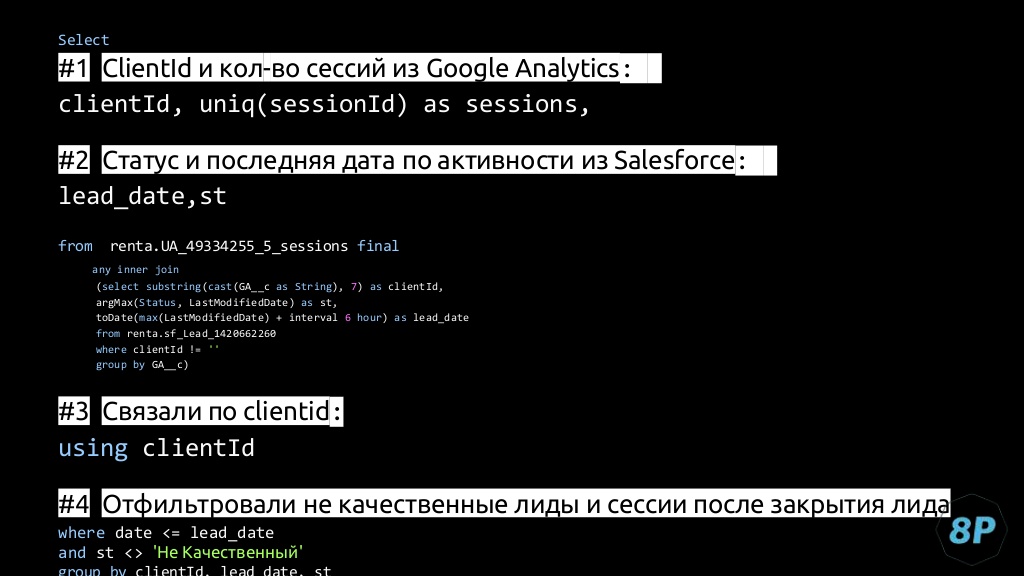
Если коротко, то работает он так.
- #2 — это первый запрос, который обрабатывает данные по таблице SalesForce. Мы его оставляем неизменным и постоянно дописываем новыми агрегатными функциями.
- Берем client ID — #1, и считаем по нему количество уникальных сессий, которые у нас есть в таблице Google Analytics.
- Далее берем статус и последнюю дату активности в SalesForce и объединяем их JOIN — #3. Это связывает их по client ID.
- Делаем фильтрацию по некачественным лидам — #4. Чтобы они не участвовали в атрибуции.
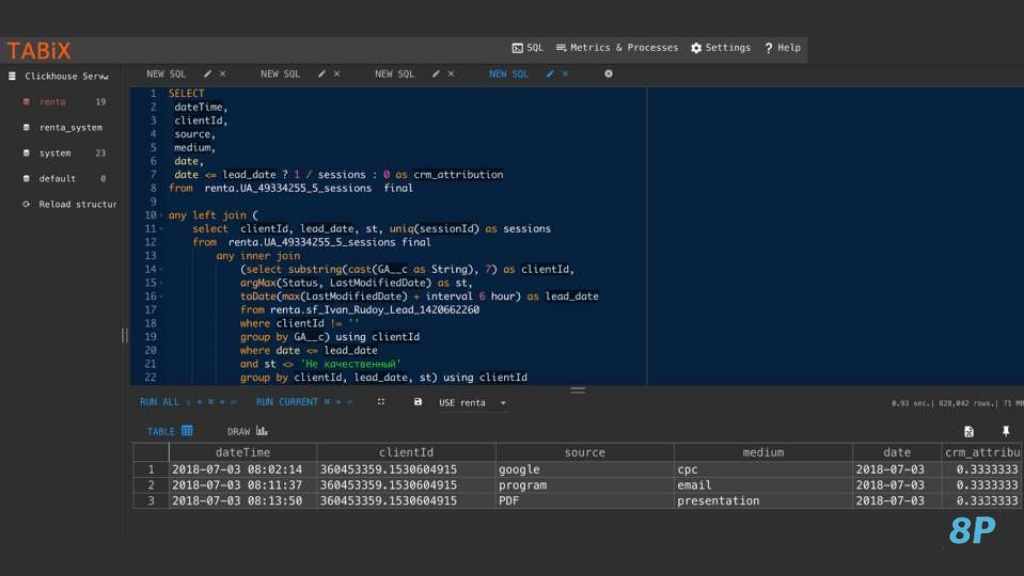
В результате мы видим, что у конкретного пользователя было три сессии и определенный статус. В рамках линейной модели атрибуции получаем такую картину:

После этого берем все данные из Google Analytics, считаем конкретную атрибуцию для пользователя. Видим, что ценность всех его визитов составляет 0,333333. В сумме это будет единица. Теперь можно четко провести параллель:
- сначала пользователь зашел по Google cpc;
- оформил заявку;
- перешел через имейл;
- в цепочке также участвовал PDF-файл, в котором была ссылка на наш сайт.
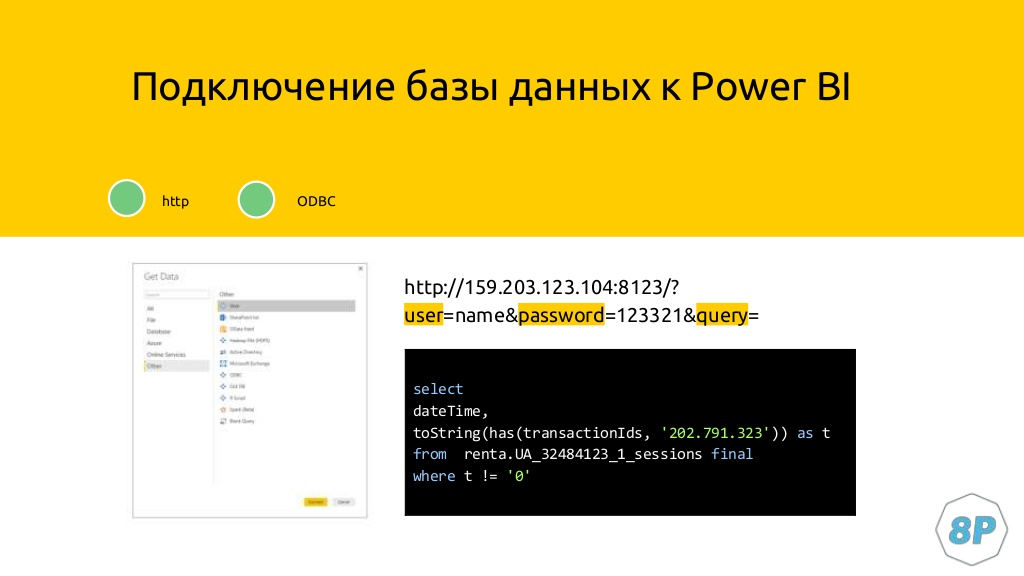
Построение отчета в Power BI
Чтобы в Power BI подтянулись данные из Google Analytics, нужно использовать веб-коннектор. Просто указываем ссылку с IP сервера, логин/пароль от него и QUERY-запрос, который мы составили для примера атрибуции.
После этого данные попадают в Power BI, где мы можем четко оценивать эффективность кампаний. Например,можем увидеть, что у нас есть кампания Display. В ее рамках у нас было:
- 5 000 гривен расходов;
- всего 30 лидов;
- из них сконвертировался 21.
Все эти отчеты группируются также формируются на уровне групп объявлений и ключевых слов. Поэтому в любой момент можно перейти в интересующую кампанию и увидеть, что там отработало.
Кейс №2: Ecommerce
Здесь мы связываем данные по transaction ID, потому что понимаем, что платим за каждую покупку. В качестве оценки воронки продаж мы используем запрос, который считает атрибуцию по прохождению человека по воронке. ClickHouse обрабатывает запрос в течение считанных секунд — а ведь там около 3 млн сессий.
Тут мы видим, что в рамках привлечения транзакции у нас было 3 session ID. Каждый из них соответствует рекламному источнику. Человек купил на 19$, мы их разбросали по определенным весам и получили конечное Revenue по каждому источнику. Если взять сумму по последнему столбцу, получится итоговое значение.
Мы подтягиваем атрибуцию в Power BI. Мы можем ввести ID заказа и увидеть, какие источники участвовали во всем этом процессе.
Резюме
- Оцениваем зрелость команды. Как показывает практика, мало кто готов ими пользоваться. Многим просто лень заходить и проверять отчеты.
- Выбираем метрики на уровне менеджмента. Учитывайте пирамиду метрик, где вы младшему специалисту, который работает с отчетами, даете самые простые метрики.
- Менеджерим процессы. В то же время у вас должен быть крутой менеджер, который может контролировать сотрудников и правильно выводить метрику эффективности каждого. Либо успешности рекламной кампании. Он может сначала контролировать срез источников. Видеть их касты, доход, процент оплачиваемых, считать ROMI. Также за этими метриками можно следить в динамике в Power BI.