
Александр Максименюк, основатель и CVO Ringostat, еще со времен университета активно работает с таблицами. Поэтому к нему обращаются за советом, как написать формулу или обработать данные. По его словам, самая частая ошибка — это слишком «тяжелые» решения для задач, которые можно решить проще. Или когда вручную делается то, что можно автоматизировать. Для тех, кто работает с таблицами Google и хотел бы делать это лучше, Александр подготовил подборку советов — от простых к сложным.
Здесь мы не будем разбирать, как создать Google Таблицу или вписывать в нее информацию. Инструкции на эту тему можно легко найти. В этой статье мы поговорим про неочевидные лайфхаки при работе с Google Sheets.
Английский интерфейс и американская локаль
Русскоязычный интерфейс для большинства понятней, но в нем кроется подвох — разделителем аргументами функции здесь является точка с запятой. В английском же языке — запятая. При этом все решения, о которых поговорим ниже, настроены под запятую. Локаль также влияет на разделитель дробной части в цифрах — в англоязычной версии точка, в русскоязычной запятая. Из-за чего появляются проблемы при импорте, например, из базы данных.
Почему именно американская локаль: в ней точно будут точки, она является нативной и самой распространенной — так что в ней минимум багов. Но есть и пара недостатков: дата представлена в формате месяц, число, год, а разделителем выступает слеш.
Проверка данных (валидация)
Особенно важна, когда разные сотрудники вручную вносят данные в документ — а значит, могут делать ошибки. Валидация настраивается в разделе Data — Data Validation и бывает двух типов:
- нестрогая валидация — если ввести данные в некорректном формате, появится окошко с сообщением об ошибке;
- строгая валидация — неправильные данные вообще не получится ввести.
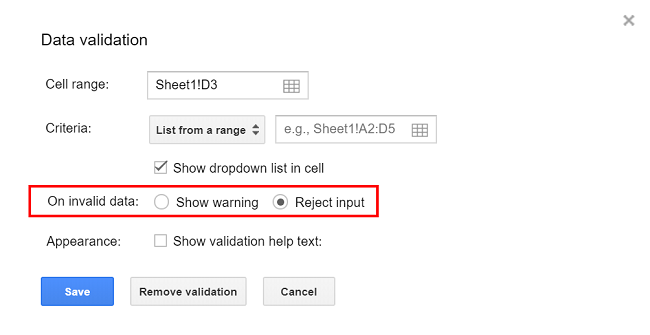
Настройка валидации
Нейминг
Называйте таблицу максимально понятно — причем не только вам, но и тем людям, которым к ней откроете доступ. Так вы избежите ситуации, когда вам нужно что-то срочно найти, а в списке открываются сплошные «новые документы». Пример названия: «Отчет об эффективности сотрудников / Иванов / Май 2018 / Компания N».
Мы обычно шутим, что документ нужно называть так, чтобы его можно было найти, стукнув во сне кулаком по клавиатуре после вечеринки в 4 утра.
Оформление
- цифры и деньги размещаем по правому краю столбца с одинаковым округлением и разделителем между разрядами — так легко определить цифры другого порядка;
- текст по левому краю столбца — мы читаем слева направо, поэтому так удобней;
- дата по центру;
- закрепляем верхние строки столбца, если документ не помещается на один экран;
- удаляем пустые ячейки и столбцы с помощью Crop Sheet — так вы будете уверены, что в документе точно нет других данных, которые просто не видны, и не достигните лимита в 400 000 ячеек на лист.
Советы, описанные в этой статье, могут показаться сложными. Особенно, если вы владелец бизнеса или маркетолог, которому отчеты нужны, чтобы понимать эффективность рекламы и окупаемость вложений в нее. В этом случае вам подойдет готовый инструмент — сквозная аналитика. Она сама подтягивает ключевые данные и автоматически рассчитывает окупаемость вложений в рекламу — ROI.
При необходимости вы также можете загружать расходы вручную. Это полезно, если вы продвигаетесь не только в тех системах, с которыми у Ringostat есть готовые интеграции. Например, вы можете оценить рентабельность вложений в SEO, баннерную рекламу и т. д
Работа с формулами
Приучайте себя делать все расчеты с использованием формул — даже если нужно посчитать 2+2. Расчетные (зависимые) величины могут быть без формул только в двух случаях:
- если импортируете готовые данные из других источников;
- когда в документе слишком много данных и он становится очень «тяжелым» — тут придется удалить часть формул, чтобы он загружался быстрее.
Общие советы для начинающих
- Смотрите на подсказки. Они появляются, как только начинаешь набирать формулу, а при нажатии на подсказку появляется более развернутое описание. В нем описаны примеры и описания условий и значений.
- Придумывайте формулы, используя базовые знания. Необязательно помнить сотни формул — иногда можно самостоятельно «собрать» то, что вам нужно. Для этого достаточно знать английский на уровне Pre-Intermediate. Например, есть документ с данными по блогу — общие (general), русскоязычная версия (ru), англоязычная (en). Необходимо транспонировать массив (об этом будет ниже) только по общим данным. Тогда формула будет выглядеть так: =TRANSPOSE(FILTER(A1:X22,A1:А = «general»)). Где: A1:X22 — весь; A1:A = blog_general — условие 1).
- Ищите готовое решение на Stack Overflow. Там есть решения для большинства задач в нескольких вариантах, и оптимальный вариант обычно отмечен галочкой. И еще один аргумент в пользу англоязычного интерфейса — в Stack Overflow все заточено под него. Если вставите решение оттуда в русскую локаль, то придется разбираться, где запятая, а где все же точка с запятой.
- Используйте F4, чтобы быстрее менять фиксированные ссылки в в формулах. Если выделить относительную ссылку и нажать один раз эту клавишу, знак $ проставится автоматически. Но учитывайте, что это не подойдет для смешанных ссылок —пример, $A1 или A$1, они наполовину относительные, наполовину абсолютные.
Название всех формул и их описания читайте в справке Google.
Модификаторы формул
IF и IFS работают для множества функций, но нужно помнить хотя бы основные:
- SUM — сумма;
- AVERAGE — среднее значение;
- COUNT — подсчет количества, например, ячеек, символов в строке, но не их содержимого.
Если добавить к ним IF, то будет проверка на одно определенное условие, а если IFS, то таких условий может быть много. И только при выполнении всех из них будут выводиться значения.
Еще одна полезная формула — UNIQUE, которая возвращает уникальные строки в указанном диапазоне, убирая дубликаты. На примере ниже таблица с источниками и каналами, названия которых дублируются. Нужно посчитать количество сессий и коэффициент конверсии для каждого из них. При этом нам нужно суммировать данные по каждому из каналов — например, все сессии из google cpc. Что мы делаем:
- выбираем уникальные значения с помощью UNIQUE;
- с помощью SUMIF проставляем условие, что суммируются все значения, если utm_source — google, а utm_medium — cpc;
- используем $, чтобы закрепить диапазон.
ARRAYFORMULA
Отображает значения, полученные с помощью формулы массива, в нескольких строках и столбцах. При своей простоте, сильно упрощает работу с таблицами. Допустим, есть большой массив данных, который нужно обработать — посчитать conversion rate на примере ниже. Мы могли бы значение одной ячейки поделить на другую и растянуть.
В чем преимущество ARRAYFORMULA:
- скорость;
- не расходуется лимит на количество формул — об этом будет ниже;
- удобство — вписываем диапазоны, нажимаем Enter, и формула все посчитала и растянула.
ARRAYFORMULA можно использовать и для более сложных задач. Допустим, нужно посчитать сумму и сделать проверку по REGEX — точному соответствию определенному тексту. Если делать проверку на соответствие регулярному выражению, то не существует формулы, которая работает с массивом.
Представим, документ, где приведено количество переходов из всех источников. Нас интересуют именно переходы из Facebook. При этом в документе есть пять меток со словом Facebook (например, Facebook_buisness) и еще три с сокращением Fb (Fb_123). Благодаря подвиду этой формулы REGEXMATCH, мы можем суммировать показатели, где в тексте есть упоминание слова Facebook и Fb.
С ARRAYFORMULA можно использовать любые формулы, кроме INDEX, SEARCH, QUERY, в некоторых случаях некорректно работает SUM и т. д.. Когда выделяете два или несколько массивов, они должны быть одинакового размера.
Еще одно применение ARRAYFORMULA — перенос данных с одного листа на другой в рамках одного документа. Допустим, в документе формируется дэшборд, в котором в котором 200 строк и тридцать столбцов. Импортируем данные на отдельный лист в том же документе, и с помощью ARRAYFORMULA затягиваем огромный диапазон — горизонтально и вертикально. Например, так можно затянуть одной формулой пять строк данных за три года
Формулы, которые важно помнить
- IMPORTRANGE — позволяет импортировать диапазон данных из документа, к которому есть доступ.
- SPLIT — разбивает текстовые данные по определенному разделителю. Например, у нас есть документ для калькуляции приоретизации features Ringostat. В одной ячейке забит ID задачи и ее описание из системы для управления проектами. В соседнюю ячейку мы затягиваем все до пробела — т. е. только ID. Дополнительно по нему можно сформировать ссылку (формула HYPERLINK) с помощью формулы CONCATENATE.
- UNIQUE — возвращает уникальные строки в указанном диапазоне, убирая дубликаты. Результат является массивом. В UNIQUE можно вставить двумерный массив и выбрать в нем уникальные строки.
- VLOOKUP и HLOOKUP — находит значения по ключу в определенной ячейке диапазона. Вернемся к примеру из пункта 2. Есть документ с ID, названием и описанием feature, ее score. Формула позволяет оттуда вытянуть название feature по списку ключей.
- TRANSPOSE — транспонировать массив, т. е. развернуть. Допустим, есть массив, в котором заголовки в первой строке, а нужно сделать так, чтобы они были столбцом. Так, данные которые располагались слева направо, перемещаются в столбец — сверху вниз. Транспонировать диапазон можно также с помощью специальной вставки paste special.
- IF — нужен в случаях, когда SUMIF и SUMIFS недостаточно.
- SORT — сортировка. Например, данные на листе нужно отсортировать по определенному критерию. В том же документе с калькуляцией скоринга features мы затягиваем массив из другого документа. Сначала убираем из него дубликаты с помощью UNIQUE, а потом сортируем по score.
Полезные фишки
- {A1:A20,C1:C20} {A1:A20;C1:C20} — дают единый массив, при этом результат зависит от разделителя. Вернемся к примеру с таблицей для приоритизации features. Нас интересуют стоблцы A, B и M. Проблема в том, что нельзя импортировать этот диапазон и вставить без столбцов — а объединение массивов это позволяет. Но опять-таки оба варианта работают в английской локали. Вариант с запятой даст горизонтальное объединение массивов, а при точке с запятой объединит данные в один столбец. В русской локали варианта с запятой не существует.
- A1&B1 — объединяет значения из нескольких строк в одну. Можно еще и так A1&» «&B1.
- «Some text» — текст оформляется двойными кавычками. Если вдруг вы используете апострофы в качестве «одинарных кавычек», учитывайте, что в Google Spreadsheets они применяются для других целей.
- Если при FALSE результате в рамках функции IF нужно вывести пустую строку, не забывайте добавить в конце разделитель =if(D2>20,true,) иначе будет подставляться FALSE.
- Если формула проставляется наперед и содержит деление, в пустых ячейках отобразится NA/0. Чтобы сделать «красивее» и вывести вместо этого пустую ячейку, формулу заворачивают в IFERROR =iferror(ARRAYFORMULA(E2:E/D2:D)).
- CTRL(CMD — для Mac) + SHIFT + V — вставить значения. Нужен, если копируете ячейки, где есть формулы, и хотите вставить просто значение. Также убирается форматирование при вставке.
- Строка редактирования формул растягивается по высоте. Для переноса строк при создании или редактировании формул используется CTRL(CMD) + Enter, перенос строки не считается символом. Так намного удобнее редактировать, особенно когда большая формула.
- F2 на ячейке открывает ее редактирование. Это особенно применимо, если вы работаете на клавиатуре и не хотите постоянно тянуться за мышкой.
- ≠ записывается как <>. Например, если вам нужно найти все значения, которые не равны определенному содержимому. Например, google cpc.
- =sum(arrayformula(if(REGEXMATCH(C2:C10,»some regEx»),D2:D10,0))) — это нужно понять для того, чтобы открылся третий глаз при работе в Spreadsheets 🙂 Александр говорит, что уже встречал много подобных кейсов.
Если документ тяжелый и с ним неудобно работать
- Используйте более легкие функции. Например, QUERY очень тяжелая. Да, у нее больше возможностей, но во многих случаях можно обойтись и VLOOKUP для тех же целей.
- Уменьшите количество IMPORTRANGE. При импорте данных из нескольких документов, каждый раз когда рендерится документ, формула берет данные оттуда, вставляет, пересчитывает и т. д. С точки зрения нагрузки, куда проще сформировать в первом документе итоговый лист со всеми значениями для импорта. А во втором создать такой же лист и импортировать туда все нужные данные. В итоге данные затянутся за один раз, и не будет пяти открытий исходного документа. Дальше эту информацию можно поместить на нужные листы для работы, например, пользуюсь ARRAYFORMULA.
- Используйте оптимальные решения. Тут помогают выводы из собственной практики. Например, при большом количестве данных =IFERROR(B1/A1) «легче», чем =IF(B17<>0,C17/B17,).
- Перейдите на внешнюю агрегацию данных. Перенесите их в BigQuery или другую базу данных, там вы можете обрабатывать данные, а Google Spreadsheets импортировать готовые значения. Для этого удобно использовать Google Apps Script (GScript).
- Уберите формулы из ячеек, которые не должны пересматриваться. Например, данные старше трех месяцев. Нажимаем CTRL + C, а потом CTRL + SHIFT + V на тех же ячейках — документ стал «легче».
Лимиты
- 400 000 ячеек, максимум 256 столбцов на лист;
- 40 000 ячеек, содержащих формулы;
- 200 листов в документе;
- 1 000 формул GoogleFinance;
- 1 000 формул GoogleLookup;
- ImportRange: 50 формул для импорта из других документов;
- 50 формул ImportData, ImportHtml, ImportFeed или ImportXm.
Рекомендуем конспект доклада с примерами дашбордов для техподдержки и отдела продаж — все они построены с помощью Spreadsheets.
Здравствуйте, как сделать привязку к данным верно? Есть список ФИО, которыми пользуются в таблице через проверку данных, а к ним уже привязываются транзакции. Но если изменить в ФИО хоть одну букву, старые выбранные значения будут бессмысленны.
Ну там вполне логичное поведение, вы фильтруете по 2-м полям, хотя по-сути вам следовало бы фильтровать только по полю с ID клиента. А поле с ФИО является вспомогательным и нужно во второй таблице для наглядности.
Я бы предложил во второй таблице с транзакциями тянуть ФИО из первой через Filter или Vlookup.