
Хотите решать нестандартные задачи с Ringostat? Например, передавать данные о звонках в собственную CRM-систему. Или построить на основе данных о звонках рекомендательную систему, которая подскажет менеджерам, какие товары предложить клиенту. В таком случае вам придётся использовать не стандартный интерфейс Ringostat, а программный — то есть API. В этом вам поможет статья от Алексея Селезнева, главы отдела аналитики агентства Netpeak.

Алексей Селезнев,
глава отдела аналитики агентства Netpeak
Я с 2014 года развиваю отдел аналитики в агентстве. А с 2016 изучаю язык программирования R — сейчас это мой основной рабочий инструмент. Для решения повседневных задач я написал более десятка пакетов, расширяющие базовый возможности языка. Также я активно популяризирую язык R среди русскоязычных аналитиков через публикации статей в медиа, включая Habr и Netpeak Journal. Выступаю на профильных конференциях с докладами по применению языка R в интернет-маркетинге.
Разумеется, я интересуюсь продуктами, с которыми работает наше агентство. В том числе и Ringostat. Это платформа позволяет получить обширный объем данных о звонках. Предоставляет графический интерфейс для построения отчетов на базе собранной информации, даже имеет нативную интеграцию с Google Data Studio. На начальных этапах этого будет достаточно. Но рано или поздно вы столкнетесь с тем, что нужны дополнительные интеграции.
В этой статье мы разберемся, как работать с Ringostat API с помощью готового пакета функций ringostat. Статья рассчитана на читателей, не знакомых с языком R и программированием.
Что такое язык R
R — это язык программирования, созданный специально для работы с данными.
Изначально он был «потомком» языка S и довольно долго использовался исключительно для академических исследований. Но в 2000-х язык был подхвачен крупными корпорациями: Facebook, Google, AirBnb и многими другими. Сегодня R очень широко используется в решении бизнес-задач — в том числе и в интернет-маркетинге.
Популярность R получил во многом благодаря появлению огромного количества дополнительных пакетов: dplyr, data.table, ggplot2 и так далее. В основном репозитории хранения R пакетов — CRAN, на данный момент опубликовано более 15000 пакетов, которые упростят решение практически любой задачи.
Что такое R пакет, и как его установить
R пакет — это сгруппированный в один проект набор функций и данных.
Каждый пакет содержит функции для решения конкретной задачи, например:
- dplyr — манипуляция данными, аналог доступных в языке SQL-операций;
- ggplot2 — имеет обширный функционал для визуализации данных;
- readr — предназначен для чтения данных из файлов различных форматов в R;
- jsonlite — для чтения JSON-структур и преобразования из/в R объекты.
Также есть пакеты, которые помогут автоматизировать рутину и настроить сбор данных интернет маркетологам:
- rgoogleads — пакет для запроса данных из Google Ads API;
- rfacebookstat — пакет для запроса статистики из рекламных кабинетов Facebook.
Это конечно далеко не исчерпывающий набор полезных пакетов. Пакет можно рассматривать как отдельное программное обеспечение. Поэтому любой дополнительный пакет изначально надо установить и при необходимости подключать в R сессии.
Устанавливаются пакеты в R командой install.packages(‘название пакета’). Для использования функционала пакета его необходимо подключить командой library(‘название пакета’>.
С чего начать изучение языка R
Синтаксис R ненамного сложнее формул Excel. Для того, чтобы немного снизить порог вхождения в язык я записал и выложил в публичный доступ видеокурс «Язык R для пользователей Excel».
Курс рассчитан на новичков, и позволит вам сделать первые шаги в изучении этого языка. В ходе прохождения курса вы научитесь основным операциям по манипуляции данными в R, и визуализации данных с помощью пакета ggplot2. К каждому уроку курса прилагаются тесты, с решением теоретических и практических задач.
Я думаю, этот курс будет вполне хорошим стартом в изучении R.
Как получить данные о звонках из Ringostat в R
Для начала скачайте и установите язык R и среду разработки RStudio. Ничего сложного в этом нет, но при необходимости вы можете посмотреть первый урок курса о котором я писал выше.
Теперь установим и подключим пакеты, которые мы будем использовать для лайфхака, описанного в статье:
install.packages(c('ringostat', 'dplyr', 'ggplot2', 'bigrquery'))
library(ringostat)library(dplyr)library(ggplot2)library(bigrquery)
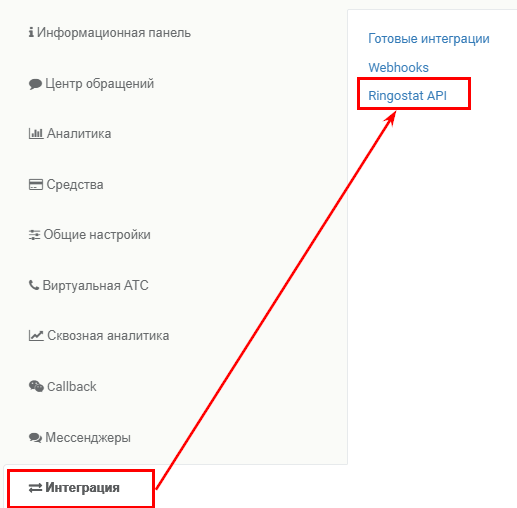
Теперь нам необходимо установить API-ключ. Получить его вы можете в веб интерфейсе Ringostat, перейдя в Интеграция — Ringostat API.
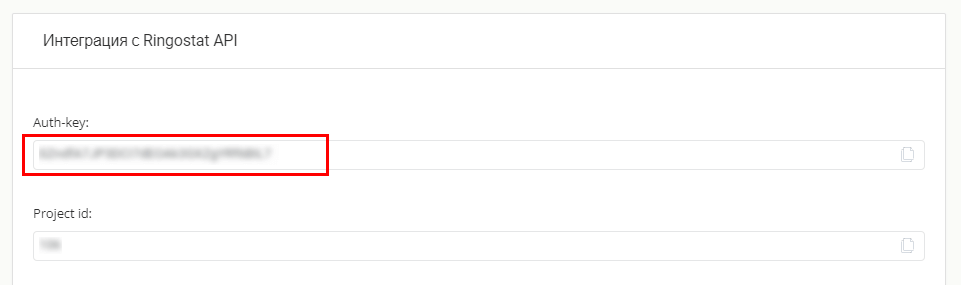
Скопируйте ваш Auth-key и используйте его в коде:# Ключ APIrs_auth('Ваш Auth-key')
Теперь мы можем запросить данные о звонках с помощью функции rs_get_call_data():
# Запрашиваем данные о звонках за последние 30 днейcalls <- rs_get_call_data( date_from = Sys.Date() - 31, date_to = Sys.Date(), fields = c("uniqueid", "calldate",
"disposition", "category_mark", "billsec", "utm_source", "call_type"))
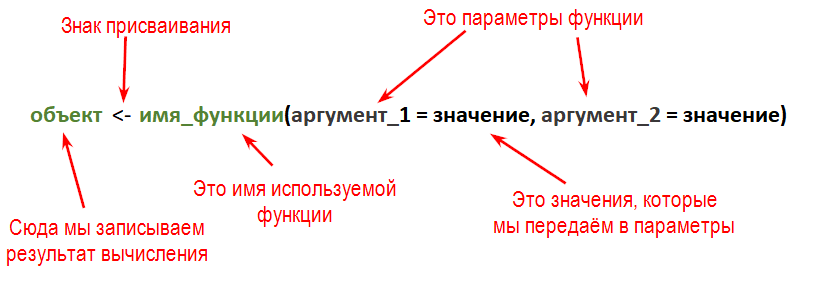
Как видите, синтаксис напоминает формулы Excel, но вместо ячейки вы присваиваете значения объектам, через стрелку <-. В остальном вы так же пишите имя нужной функции, открываете круглые скобки и передаете значения в аргументы функции.
В функции rs_get_call_data() вам доступны следующие аргументы:
- date_from — дата начала отчетного периода;
- date_to — дата завершения отчетного периода;
- fields — список полей, с данными о звонках, которые вы получите от API:
- caller - Номер звонящего;
- dst - Куда звонили;
- pool_name — имя пула, т. е. группы номеров, в которой расположен номер;
- disposition — статус звонка;
- calldate — дата и время звонка;
- category_mark — ценность звонка, ее вы присваиваете самостоятельно в настройках категорий звонков;
- duration - Длительность звонка(ожидание + разговор);
- call_type — тип звонка: входящий, исходящий, callback;
- waittime — время ожидания ответа на звонок;
- billsec — длительность разговора;
- connected_with — с кем соединен;
- call_counter — какой по счету звонок;
- proper_flag — статус звонка: целевой;
- repeated_flag — статус звонка: повторный;
- utm_source — источник перехода;
- utm_medium — канал перехода;
- utm_campaign — кампания объявления;
- utm_content — содержание объявления;
- utm_term — ключевое слово объявления;
- uniqueid — ID звонка в системе Ringostat;
- category_number — категория звонка;
- employee_number — код сотрудника;
- employee_mark — оценка сотруднику за звонок;
- client_id — UUID посетителя;
- remote_ip — IP посетителя;
- referrer — URL страницы, с которой посетитель перешел на сайт;
- landing — страница входа посетителя;
- recording — ссылка на аудиозапись;
- recording_wav — ссылка на аудиозапись в формате wav;
- call_card — ссылка на карточку звонка для номера, с или на который звонили;
- additional_number — добавочный номер, введенный в голосовом меню;
- has_recording — значение 1 или 0, в зависимости от того, был ли записан разговор при звонке;
- scheme_name — название схемы переадресации, на которую был направлен звонок;
- duration_ms — длительность разговора в миллисекундах (duration*1000);
- employee_fio — ФИО сотрудника из раздела «Настройки» — «Сотрудники»;
- department — название отдела/отделов, к которым относится сотрудник;
- caller_number — номер, который отобразился клиенту при исходящем звонке;
- filters — фильтры, для выборки данных подпадающих под условие по значением полей;
- merge — объединение выборки по номеру звонящего:
- 0 – не объединять;
- 1 – объединять за каждые 24 часа;
- 2 – объединять за всё время;
- order — сортировка выборки.
Итак, мы разобрались как запросить данные о звонках из своего аккаунта Ringostat в R, но что с ними дальше делать?
Как визуализировать данные о звонках в R
Тут нам на помощь приходит пакет ggplot2, это один из наиболее популярных пакетов на R. Но, перед тем как визуализировать данные, нам необходимо привести их к нужному виду, для этой цели мы будем использовать функции пакета dplyr.
Следующий пример кода позволяет построить линейный график о количестве звонков, с разбивкой по типу звонка.
# визуализируем к-во звонков по днямcalls %>% mutate(calldate = as.Date(calldate)) %>% # оставляем только дату, убрав значение времени group_by(calldate, call_type) %>% # группируем данные по дате и типу звонка summarise(calls = n_distinct(uniqueid)) %>% # считаем к-во звонковqplot(data = ., x = calldate, y = calls, group = call_type, colour = call_type, geom = c('line', 'point'), main = 'Количество звонков по дням', xlab = 'Дата', ylab = 'К-во звонков')
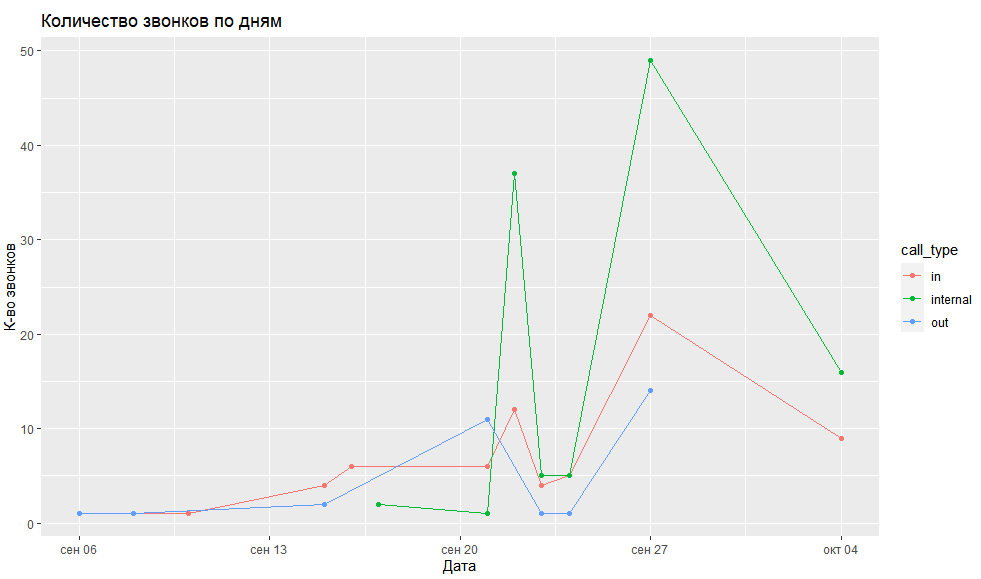
Функции mutate(), group_by() и summarise() позволяют нам привести данные к нужному виду, а точнее:
- mutate() переопределяет столбец calldate, убрав из его значения информацию о времени звонка, т.к. нам необходимо построить график по дате;
- group_by() группируют нашу таблицу по столбцам calldate и call_type;
- summarise() подсчитывает количество звонков в каждой группе.
Т. е. после применения этих трех функций у нас остаётся таблица с тремя столбцами:
- calldate — дата звонка;
- call_type — тип звонка;
- calls — количество звонков.
Далее функция qplot() строит график, принимая следующие аргументы:
- data — входящие данные, мы ставим точку, т. к. в нашем случае это данные, являющиеся результатом выполнения предыдущих операций, которые в функцию qplot мы передали через пайплайн-оператор %>%;
- x, y — что отобразить по осям X и Y соответственно;
- group — позволяет группировать данные, в нашем случае мы группируем данные по типу звонка;
- colour — позволяет задать переменную, т. е. столбец, который будет определять цвет линий, у нас он зависит от типа звонка;
- geom = отвечает за тип графика, у нас он линейный с точками;
- main, xlab, ylab — заголовки графика и осей.
Приведу еще один пример визуализации — построим график боксплот, так называемый «ящик с усами» или диаграмма размаха. Она будет отображать длительность входящих звонков с разбивкой на каналы их получения.
# длительность входящих звонков по источникамcalls %>% filter(call_type == 'in') %>% qplot( data = ., x = utm_source, y = billsec, geom = c('boxplot'),
fill = utm_source, main = 'Длительность звонка по источникам', xlab = 'Источник', ylab = 'Длительность разговора'
)
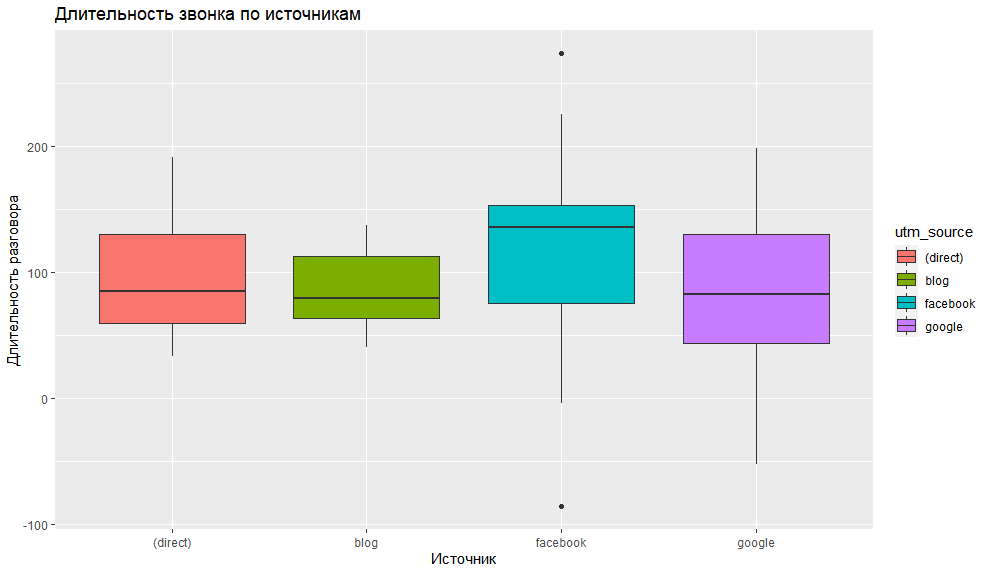
В этом примере мы изменили тип графика, используя аргумент geom. И отфильтровали данные по типу звонка, оставив только входящие звонки.
Пакет ggplot2 очень функциональный — продемонстрировать всю его мощь в одной вводной статье невозможно. Если хотите ознакомится с его возможностями более глубоко, рекомендую почитать книгу Сергея Мастицкого «Визуализация данных с помощью GGPLOT2».
Как записать данные о звонках в Google BigQuery
Мы уже научились запрашивать и визуализировать данные о звонках средствами языка R, теперь разберёмся с тем, как передать эти данные на хранение в одну из наиболее популярных облачных баз данных Google BigQuery. Для этой цели мы установили и подключили пакет bigrquery.
ВАЖНО: для записи данных в Google BigQuery у вас уже должен быть создать проект в Google Cloud. Если не знаете как его создать почитайте статью “Google BigQuery — зачем нужна облачная база данных”. В ней я подробно описал все подготовительные работы.
Итак, изначально для работы с Google BigQuery API надо пройти авторизацию. Для этого используйте функцию bq_auth(), указав свой Google-аккаунт.bq_auth('[email protected]')
Далее, используя функции bq_table(), указываем в какой проект, набор данных и таблицу необходимо записать данные. А функция bq_table_upload() позволяет управлять параметрами записи.
# отправка данных в Google BigQuerybq_table(project = "id проекта в BigQuery",
dataset = "id набора данных в BigQuery",
table = "название таблицы в BigQuery") %>%
bq_table_upload(values = calls,
create_disposition = "CREATE_IF_NEEDED",
write_disposition = "WRITE_APPEND")
Аргумент create_disposition позволяет указать, что делать если указанной таблицы нет в наборе данных. Мы указали CREATE_IF_NEEDED, что означает создать таблицу по необходимости.
Аргумент write_disposition позволяет указать, что делать если заданная таблица уже существует и содержит данные:
- WRITE_APPEND - дописать данные;
- WRITE_TRUNCATE - перезаписать данные;
- WRITE_EMPTY - вернуть ошибку, если таблица уже существует и содержит данные.
Эта статья всего лишь небольшой экскурс в язык R и возможности по работе с API различных сервисов. На самом деле зачастую возможности ограничиваются лишь вашей фантазией.
Если вас заинтересовал язык R подписывайтесь на мой Telegram и YouTube-канал R4marketing.